Humans are adept at recognizing patterns. We can identify the difference between cats and dogs, bananas and orange, cars and airplane. Children differentiate man and woman by their hairs. All of these have visual characteristics such as color and shape that allow us to differentiate one from another. Computers which can process information a lot faster than humans can be trained or programmed to recognize such patterns.
In this activity, 15 images of 200 x 200 pixels of soccer balls and basketballs are taken from google images. As such, it is the task of the program to differentiate the soccer balls from footballs. Figure 1 and 2 show the 30 images.
 |
| Figure 1: Fifteen Images of Soccer/Footballs |
 |
| Figure 2: Fifteen Images of Basketball |
The average rgb color of the images are taken per image. Their colors are then plotted. Figure 3 represents the image. The Green dots represent the average rgb of the basketball, and the blue dot represent the average rgb of the footballs.
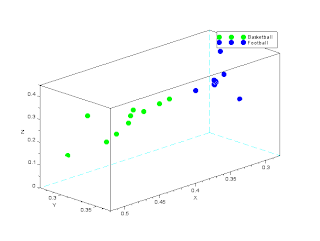 |
| Figure 3: 3-D plot of trained images (both Basketball and Football) |
 |
| Figure 4: Distance plot between Test Basketball Images |
From Figure 4, Row 1 represents the distance of the test basketball image against the trained basketball image. Row 2 represents the distance of the test basketball image against the trained soccer image. Evidently, for all columns, the distance of the trained basketball image is always smaller than the trained soccer image. This shows that the basketball images in terms of their rgb components is much closer to the color of the basketball which is exactly what we want.
The result is 5/5 or 100% recognized. The weight of recognition however varies.
 |
| Figure 5: Distance plot between Test Soccer/Football Images |
In Figure 5, same method was applied except the images are now trained football images. Row 1 represents the trained Basketball images and row 2 represents the trained soccer images. As shown, Row 2 is always less than Row 1. This means all images of the test scoccer are closer to the average trained soccer images.
The result is 5/5 or 100% of the images are recognized.
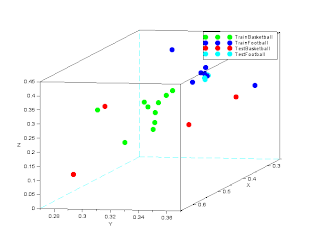 |
| Figure 6: Location of the Test vs. Trained Images |
Code Snippet:
//Training
Bred = [];
Bgreen = [];
Bblue = [];
for j = 1: 10
filename = double(imread(['C:\Users\Phil\Desktop\Academic Folder\Academic Folder 13-14 First Sem\AP 186\Activity14\BasketBalls\Basket'+string(j)+'.jpg']));
Bred = [Bred mean(filename(:,:,1))];
Bgreen = [Bgreen mean(filename(:,:,2))];
Bblue = [Bblue mean(filename(:,:,3))];
end
Bmeanrgb = Bred + Bblue + Bgreen;
param3d(Bred./Bmeanrgb,Bgreen./Bmeanrgb,Bblue./Bmeanrgb);
B = get('hdl');
B.foreground = 6;
B.line_mode = 'off';
B.mark_mode = 'on';
B.mark_size = 1;
B.mark_foreground = 3;
Sred = [];
Sgreen = [];
Sblue =[];
for j = 1: 10
filename = double(imread(['C:\Users\Phil\Desktop\Academic Folder\Academic Folder 13-14 First Sem\AP 186\Activity14\SoccerBalls\Football'+string(j)+'.jpg']));
Sred = [Sred mean(filename(:,:,1))];
Sgreen = [Sgreen mean(filename(:,:,2))];
Sblue = [Sblue mean(filename(:,:,3))];
end
Smeanrgb = Sred + Sblue + Sgreen;
param3d(Sred./Smeanrgb,Sgreen./Smeanrgb,Sblue./Smeanrgb);
B = get('hdl');
B.foreground = 6;
B.line_mode = 'off';
B.mark_mode = 'on';
B.mark_size = 1;
B.mark_foreground = 2;
hl=legend(['Basketball';'Football';])
Bmean = mean(Bred)+mean(Bgreen)+mean(Bblue);
Smean = mean(Sred)+mean(Sgreen)+mean(Sblue);
//Testing
BB = [];
SB = [];
Bredt = [];
Bgreent = [];
Bbluet = [];
for j = 11: 15
filename = double(imread(['C:\Users\Phil\Desktop\Academic Folder\Academic Folder 13-14 First Sem\AP 186\Activity14\BasketBalls\Basket'+string(j)+'.jpg']));
BB = [BB sqrt((mean(filename(:,:,1))-mean(Bred))^2 + (mean(filename(:,:,2)-mean(Bgreen)))^2+(mean(filename(:,:,3)-mean(Bblue)))^2)];
SB = [SB sqrt((mean(filename(:,:,1))-mean(Sred))^2 + (mean(filename(:,:,2)-mean(Sgreen)))^2+(mean(filename(:,:,3)-mean(Sblue)))^2)];
Comparison1= [BB;SB];
Bredt = [Bredt mean(filename(:,:,1))];
Bgreent = [Bgreent mean(filename(:,:,2))];
Bbluet = [Bbluet mean(filename(:,:,3))];
end
Bmeanrgbt = Bredt + Bbluet + Bgreent;
param3d(Bredt./Bmeanrgbt,Bgreent./Bmeanrgbt,Bbluet./Bmeanrgbt);
B = get('hdl');
B.foreground = 6;
B.line_mode = 'off';
B.mark_mode = 'on';
B.mark_size = 1;
B.mark_foreground = 5;
Sredt = [];
Sgreent = [];
Sbluet = [];
BS = [];
SS = [];
for j = 11: 15
filename = double(imread(['C:\Users\Phil\Desktop\Academic Folder\Academic Folder 13-14 First Sem\AP 186\Activity14\SoccerBalls\Football'+string(j)+'.jpg']));
BS = [BS sqrt((mean(filename(:,:,1))-mean(Bred))^2 + (mean(filename(:,:,2)-mean(Bgreen)))^2+(mean(filename(:,:,3)-mean(Bblue)))^2)];
SS = [SS sqrt((mean(filename(:,:,1))-mean(Sred))^2 + (mean(filename(:,:,2)-mean(Sgreen)))^2+(mean(filename(:,:,3)-mean(Sblue)))^2)];
Comparison2 = [BS;SS];
Sredt = [Sredt mean(filename(:,:,1))];
Sgreent = [Sgreent mean(filename(:,:,2))];
Sbluet = [Sbluet mean(filename(:,:,3))];
end
Smeanrgbt = Sredt + Sbluet + Sgreent;
param3d(Sredt./Smeanrgbt,Sgreent./Smeanrgbt,Sbluet./Smeanrgbt);
B = get('hdl');
B.foreground = 6;
B.line_mode = 'off';
B.mark_mode = 'on';
B.mark_size = 1;
B.mark_foreground = 4;
h2=legend(['TrainBasketball';'TrainFootball';'TestBasketball';'TestFootball'])
References:
1. Soriano, Jing, Act14 Pattern Recognition, 2013